Nvidia DGX Spark
How We Built a Production RAG System on DGX Spark in Costa Rica (and What It Cost)
A real-world deep dive into deploying GPT-OSS on NVIDIA DGX Spark, optimizing Ollama for production inference, and streaming responses through Fastly — from a Latin American datacenter serving nearshore and regional customers.
The problem we were solving
A Latin American enterprise came to us with a concrete challenge: they needed production-grade retrieval-augmented generation (RAG) inference for Spanish-language queries, with three non-negotiable constraints.
First, data residency. Their regulatory posture and customer contracts meant query data could not leave the region. Cloud API providers — even when technically compliant — were a hard political sell internally.
Second, predictable cost at scale. Their projected query volume made per-token API pricing painful. Back-of-envelope math showed their annual spend on commercial LLM APIs would exceed the capital cost of owning dedicated inference hardware within roughly nine months.
Third, latency. Their users expected conversational response times. Round-tripping to US-East or European endpoints added enough network overhead to degrade the experience, especially for streaming token responses where time-to-first-token is what users actually perceive.
The solution we landed on: an NVIDIA DGX Spark running GPT-OSS models via Ollama, sitting behind a vector store and orchestration layer, with Fastly at the edge handling Server-Sent Events (SSE) streaming. Deployed inside our datacenter in Costa Rica, peered directly through AS52423.
This post walks through the architecture, the optimizations that actually moved the needle, and the honest economics of running production AI infrastructure in Latin America in 2026.
Why on-prem, why DGX Spark, why Costa Rica
Before getting into the technical detail, the "why" matters — because the architecture only makes sense if you understand the decision framework behind it.
The cost comparison
At the query volume we were targeting, the economics broke down roughly like this:
| Option | Approximate monthly cost | Notes |
|---|---|---|
| Commercial API (GPT-4 class) | $18,000–25,000 | Scales linearly with volume; no data residency |
| Cloud GPU inference (H100, on-demand) | $12,000–18,000 | Data residency still unresolved; egress costs extra |
| Cloud GPU inference (reserved) | $7,000–10,000 | Better economics, still outside the region |
| DGX Spark | $1,670-1,900 | Including a dedicated firewall and unlimited 500mbps uplink |
For this customer's profile, owned hardware in-region was several times cheaper than any cloud option once steady-state volume arrived. The break-even point against reserved cloud GPU was somewhere around month seven.
Why DGX Spark specifically
DGX Spark is NVIDIA's compact AI workstation built around the GB10 Grace Blackwell Superchip. It's designed for local model development and inference at meaningful scale — 128 GB of unified memory, enough bandwidth to run mid-sized open models comfortably, and a form factor that fits in a standard rack without the power and cooling demands of an H100 server.
For the use case — production inference on open-weight models in the 20B–70B parameter range — it hits a sweet spot. You're not training foundation models on it, but for serving quantized GPT-OSS, Llama-class, and Mistral-class models to real users, it delivers.
Why Costa Rica
Three reasons, and they're all practical rather than patriotic.
Latency. For users across Central America and the northern half of South America, Costa Rica beats Miami, Dallas, and São Paulo on round-trip time in most scenarios. For nearshore US customers operating in the Central or Eastern timezones, the latency penalty versus US-East is small — often under 40 ms.
Peering. Our AS52423 position gives us direct interconnects that matter for this kind of workload. SSE streaming is sensitive to jitter and packet loss more than to raw bandwidth, and clean peering paths make a measurable difference in perceived response quality.
Regulatory fit. For LATAM enterprises with data residency requirements, hosting in-region with a local entity solves problems that no amount of cloud provider compliance documentation will fully resolve.
The architecture
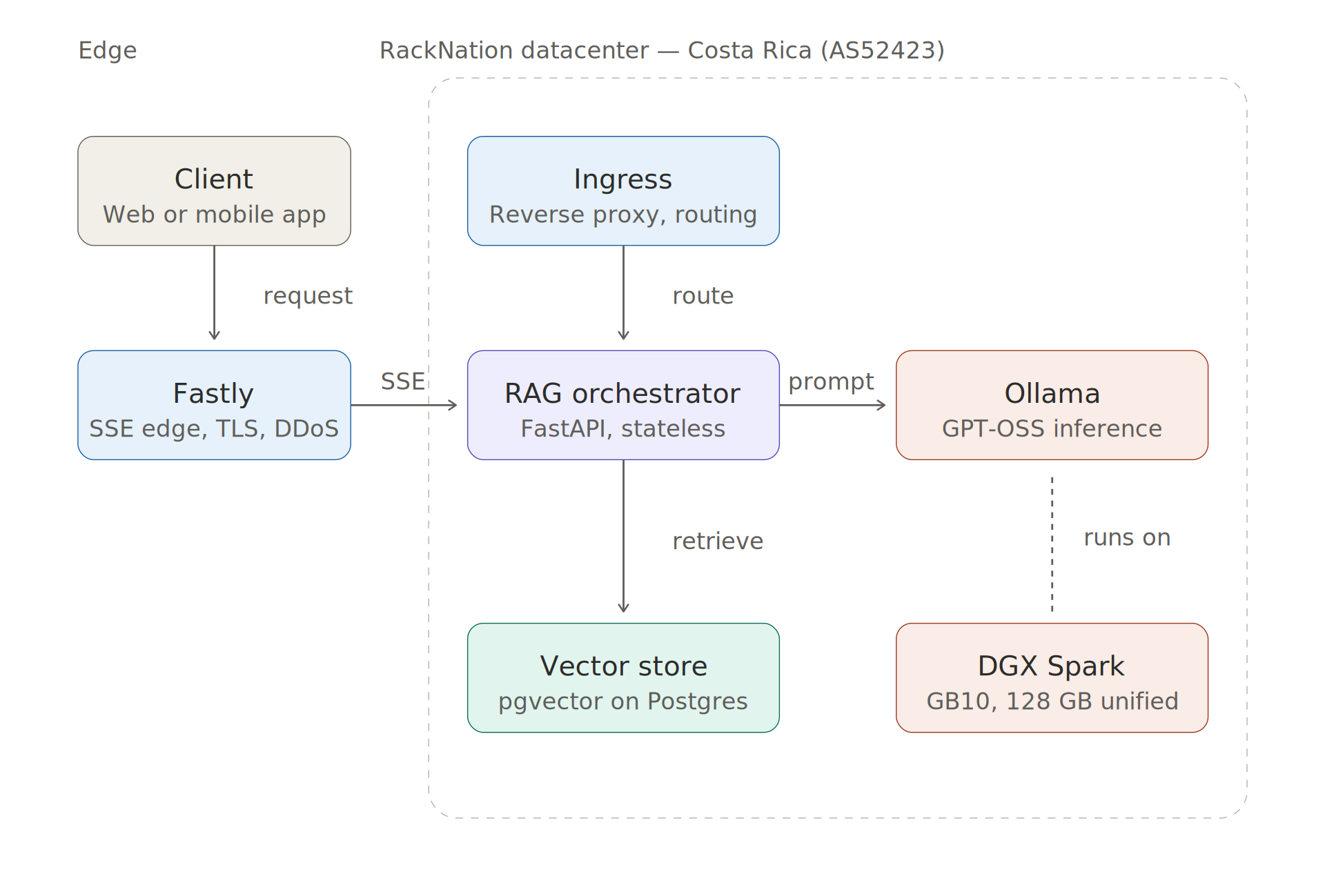
"End-to-end architecture: client → Fastly edge (SSE) → RackNation ingress → RAG orchestrator → Ollama on DGX Spark + pgvector store"
The flow is straightforward: a user query enters through Fastly at the edge, hits our ingress layer in Costa Rica, gets handled by a stateless orchestrator that performs vector retrieval and prompt construction, then streams a response from Ollama running on DGX Spark back to the client over SSE.
A few notes on the choices.
Fastly at the edge. We use Fastly for SSL termination, DDoS absorption, and — critically — SSE streaming. Fastly handles long-lived streaming connections well, and its edge presence means the first TCP handshake happens close to the user even when the inference backend is in Costa Rica.
The orchestrator. A thin Python service (FastAPI) that receives user queries, performs vector retrieval, builds the prompt with retrieved context, and streams the response from Ollama back to the client. Stateless, horizontally scalable, runs in its own VM on our Proxmox cluster.
Vector store. We went with pgvector on a dedicated Postgres instance. For this customer's corpus size (under 10M embeddings), it's more than sufficient, operationally simpler than running a dedicated vector database, and keeps their existing Postgres expertise relevant.
Ollama on DGX Spark. This is where we spent the most time, and where the interesting engineering lives.
Why Ollama over vLLM, TGI, or llama.cpp directly
We evaluated all of them. The decision came down to three factors:
- Operational simplicity. Ollama's model management — pulling, swapping, keeping multiple models warm — is genuinely good. For a production deployment where you occasionally need to A/B test models or roll forward/back, this matters.
- Good-enough performance. For our concurrency profile (tens of concurrent users, not hundreds), Ollama's throughput is within striking distance of vLLM. The gap closes further once you optimize.
- Reasonable footprint. It plays nicely with systemd, exposes clean HTTP APIs, and doesn't require a PhD in CUDA to operate.
vLLM would have been the right choice if we needed to serve hundreds of concurrent requests with maximum tokens-per-second. For this workload, the operational tradeoffs favored Ollama.
Ollama performance optimization: what actually moved the needle
This is the section most readers came for. Here's what we learned getting Ollama from out-of-the-box defaults to production-ready throughput on DGX Spark.
Baseline (before optimization)
Running GPT-OSS at its default Ollama configuration, on a single DGX Spark unit, with no tuning:
- Tokens/sec (single request): ~42
- Time-to-first-token (P50): 780 ms
- Time-to-first-token (P95): 1,400 ms
- Concurrent requests before degradation: 3
- GPU memory utilization: ~58%
Respectable, but not production-ready for the target concurrency.
Optimization 1: Model loading strategy
Out of the box, Ollama will unload a model from VRAM after a few minutes of inactivity. For a RAG system with spiky traffic, this is disastrous — every user whose query arrives during a cold-start window eats 8–15 seconds of model-loading time.
The fix: OLLAMA_KEEP_ALIVE=-1 for the production model, combined with careful memory budgeting so we know exactly what fits in VRAM simultaneously.
We keep the primary GPT-OSS model permanently resident, plus one smaller model (for query classification and safety filtering) also always loaded. Any experimental or fallback models are lazy-loaded on demand.
Impact: Eliminated cold-start latency entirely for the primary model. Time-to-first-token P95 dropped from 1,400 ms to under 500 ms.
Optimization 2: Concurrency and batching
Ollama's OLLAMA_NUM_PARALLEL setting controls how many requests it processes concurrently per model. The default is conservative.
We tuned this based on actual VRAM headroom and measured behavior. For GPT-OSS on our DGX Spark config, OLLAMA_NUM_PARALLEL=4 turned out to be the sweet spot — higher values caused VRAM pressure and occasional OOM kills under sustained load; lower values left throughput on the table.
Combined with this, OLLAMA_MAX_LOADED_MODELS=2 prevents Ollama from trying to load additional models when VRAM is tight.
Impact: Concurrent request capacity went from 3 to 11 before latency degradation kicked in. Aggregate tokens/sec under concurrent load roughly tripled.
Optimization 3: Context window discipline
This one's less about Ollama and more about how we build prompts. Naive RAG implementations stuff as much retrieved context as possible into every prompt, on the theory that "more context = better answers."
In practice, past a certain point, more context means slower inference and worse answers (the model gets distracted by marginally relevant chunks).
We tuned our retrieval to return the top-k chunks where k is dynamic based on chunk relevance scores — typically 4–8 chunks rather than a fixed 20. Combined with aggressive chunk deduplication in the retrieval layer, average prompt length dropped by roughly 40%.
Impact: Median tokens/sec jumped from 42 to 67. Answer quality, measured by human evaluation on a held-out test set, actually improved slightly.
Optimization 4: Quantization choice
GPT-OSS is available in multiple quantizations. We tested Q4_K_M, Q5_K_M, Q6_K, and Q8_0 against a benchmark of representative queries with human-rated outputs.
The finding: Q5_K_M was the best tradeoff for this workload. Q4_K_M was noticeably faster but produced Spanish output with subtle grammatical degradation that human reviewers flagged. Q8_0 was higher quality but the speed penalty wasn't justified by a quality gain our users could perceive.
This kind of finding only comes from actually benchmarking on your specific corpus and language. Don't assume the online benchmarks apply to your use case — especially for non-English deployments.
What didn't work
A few things we tried that didn't pan out, for completeness:
- Running two Ollama instances on the same DGX Spark to partition models. It doesn't help — Ollama's internal scheduling already handles this better than process-level partitioning.
- Flash Attention tuning. Not meaningful for our workload at this concurrency level; the gains were in the noise.
- Custom CUDA graph capture. Too much operational complexity for too little gain in the Ollama context.
After optimization
| Metric | Baseline | Optimized | Improvement |
|---|---|---|---|
| Tokens/sec (single request) | 42 | 67 | +60% |
| Time-to-first-token (P50) | 780 ms | 210 ms | -73% |
| Time-to-first-token (P95) | 1,400 ms | 480 ms | -66% |
| Concurrent requests before degradation | 3 | 11 | +267% |
| GPU memory utilization | 58% | 81% | Better utilization |
Fastly and SSE streaming: the edge layer
Streaming LLM responses over HTTP is a solved problem in principle and a pain in the details. Server-Sent Events is the right primitive — simpler than WebSockets, works through standard HTTP infrastructure, no protocol upgrade dance.
The non-obvious issues we ran into:
Buffering. Fastly's default behavior for some content types is to buffer responses before delivery. For SSE, you need to ensure the Content-Type: text/event-stream header is preserved end-to-end and that Fastly's VCL doesn't trigger buffering heuristics. We explicitly disabled beresp.do_stream = false (i.e., set streaming on) for the inference endpoint.
Timeouts. Default timeouts are way too aggressive for LLM streaming, where a response can legitimately take 30+ seconds to complete. We bumped first_byte_timeout and between_bytes_timeout at the Fastly layer, and matched them at the origin.
Connection keepalive and idle detection. Some intermediate proxies and mobile carrier NATs will kill connections they think are idle, even when SSE data is flowing. We send periodic SSE comments (: keepalive\n\n) every 15 seconds to keep the pipe open. Cheap insurance.
Error signaling. SSE has no native error signaling once the stream starts. We adopted a convention of sending a final event with event: error and structured JSON payload if anything goes wrong mid-stream, so the client can surface meaningful errors rather than just seeing the connection close.
What we monitor
Observability matters more for LLM inference than for traditional web workloads, because the failure modes are subtler. A slow endpoint that still returns is harder to catch than a 500 error.
The metrics we actually watch:
- Time-to-first-token. P50, P95, P99. This is what users perceive as "fast" or "slow."
- Tokens per second under load. Measured at the Ollama level, bucketed by concurrency.
- GPU utilization and VRAM headroom. If VRAM headroom drops below 10%, something's about to break.
- Queue depth at Ollama. If requests queue up, latency degrades before throughput does.
- Retrieval latency. pgvector query times, separately from inference.
- End-to-end request duration by component. Split into retrieval, prompt building, inference, streaming. Makes it obvious which layer to blame when things get slow.
Alerts fire on sustained P95 latency above threshold, VRAM headroom below threshold, and any Ollama restart events. We learned to alert on Ollama restarts the hard way — silent restarts had been masking an intermittent memory leak for a week before we noticed.
The economics, honestly
For this customer, at steady-state volume, the cost per million tokens works out to roughly $0.80–$1.20 including amortized hardware, power, cooling, and colocation. That compares to roughly $15–30 per million tokens on commercial APIs for comparable model class, and roughly $3–6 per million tokens on reserved cloud GPU.
The break-even math:
- If you're doing under ~50M tokens/month, commercial APIs are almost certainly cheaper than owning hardware, once you account for the operational overhead.
- Between 50M and 200M tokens/month, it depends heavily on your latency and compliance requirements. Reserved cloud GPU is often the right answer.
- Above ~200M tokens/month with regional data residency needs, owned hardware in-region starts to dominate on both cost and latency.
This isn't universal — your mileage varies based on model size, query patterns, and how much you value the non-cost factors. But the framework holds: model your actual volume, be honest about your compliance requirements, and do the math before assuming cloud is always cheaper.
What we'd do differently
In the spirit of honest retrospective:
We over-engineered the orchestration layer initially. The first version had elaborate circuit breakers, retry logic, and multi-model fallback. In production, almost none of it fired. We simplified significantly in version two.
We underestimated observability investment. We thought standard APM tooling would cover it. It didn't — LLM workloads need custom instrumentation to be useful, and we built that retroactively rather than proactively.
We should have benchmarked quantizations earlier. We spent weeks optimizing Q8_0 before realizing Q5_K_M was the better operating point. Start with quantization benchmarking, then optimize.
Capacity planning for spiky traffic is harder than it looks. Our initial capacity model assumed smooth load. Real traffic has spikes, and DGX Spark's concurrent request capacity is bounded by VRAM, not compute. We now provision with more headroom than raw throughput math suggests.
When this architecture makes sense
If you're evaluating whether to build something similar, the honest answer is: it depends on your scale, your compliance posture, and your latency requirements.
This architecture is a good fit when:
- You're processing enough tokens monthly to justify dedicated hardware (generally above ~100M tokens/month, depending on model class)
- You have regional data residency or compliance requirements that make cloud API use difficult
- Your users are concentrated in Latin America, or you're serving nearshore US workloads where Costa Rica's latency profile helps
- You want predictable costs rather than per-token pricing that scales with success
It's not the right fit if:
- You need frontier model capabilities (GPT-4.5, Claude Opus, Gemini Ultra class) — open models aren't at parity there yet
- Your volume is low enough that API pricing is genuinely cheaper
- You need to serve hundreds of concurrent users per GPU — you'd want a different hardware profile and likely vLLM instead of Ollama
- Your team doesn't have, or doesn't want to build, operational capability for running inference infrastructure
Getting in touch
If you're evaluating production AI infrastructure for Latin America or nearshore deployment — whether that's colocation for your own GPU hardware, managed inference on DGX Spark like the deployment described here, or consulting on the architecture — we're happy to talk.
RackNation operates out of Costa Rica (AS52423) with direct peering, meaningful GPU capacity, and a team that's actually run this stack in production. You can reach us at sales@racknation.cr or read more about our AI infrastructure services at https://www.racknation.cr/private-ai-as-a-service.